
cargo-snippet にPRを出し、爆速でmergeされました
cargo-snippet というスニペット生成ツールがあります。doc comment 内にバックスラッシュなどを書くと正しくスニペット化されないバグがあり、その修正をしました。
cargo-snippet とは
hatooさん作の、スニペット生成ツールです。以下の Qiita にて使い方がまとめられています。
Rust で競技プログラミングをするときの"スニペット管理"をまじめに考える(cargo-snippet の紹介) - Qiita
このツールが素晴らしいのは、ユニットテストを書いて、想定通りの動きをすることを保証できているコード片を使うことができる、という点です。
コード片に #[snippet] とつけるだけで、自動で Neosnippet や VSCode 形式のスニペットを生成してくれるため、以下のような流れで安心・安全なスニペット開発をすることができます。
- コード片だけを管理するリポジトリを用意
- その中でユニットテストを完備したスニペットを書く
cargo testが通ることを確認cargo snippetでスニペットを自動生成する- 生成されたスニペットを普段使っているエディタに登録
テストを通っているという安心感はとてもよいものです。
バグがあった
そんな cargo-snippet の v0.6.2 にはバグがありました。
doc comment (/// ほげ のように、スラッシュ3つのあとに書くやつです) の中でバックスラッシュを使うと、バックスラッシュの個数が2倍になってスニペットとして出力されてしまう、というバグでした。
/// foo\bar
#[snippet]
fn hoge() {}
をスニペット出力すると、以下のようになってしまっていました。
/// foo\\bar
fn hoge() {}
これはスニペットの中でアスキーアートを描きたい人にとっては由々しき問題です。
doc comment の仕組みと cargo-snippet の苦悩
cargo-snippet では、syn - Rust や proc_macro2 - Rust といったクレートを使って、入力された Rust コードを抽象構文木 (AST) に変換し、#[snippet] アトリビュートが付与されているアイテムをよしなに集めてくる、といった処理が行われています。
doc comment は、人間が書くときには /// foo のようにスラッシュ3つのスタイルで書かれることがほとんどだと思いますが、これは Rust コンパイラによって内部で #[doc = "foo"] というようなアトリビュートに変換されて処理されます。つまり、/// foo という書き方は、#[doc = "foo"] という書き方のシンタックスシュガーになっているということです。
syn, proc_macro2 はこの挙動を再現していて、/// foo と書いてある Rust コードを食わせ、構築された AST を再度文字列化させてみると、 #[doc = "foo"] というように出力されます。
古いバージョンの cargo-snippet ではこの挙動の影響を受けていて、
/// foo
#[snippet]
fn hoge() {}
をスニペット出力すると、以下のように #[doc = "foo"] となってしまっていました。
#[doc = "foo"]
fn hoge() {}
この問題に対応するため、#[doc = "foo"] という形式の doc comment を /// foo へと再糖化(という日本語は存在するのか?)するロジックを内部に実装しています。実装したのは僕で、こちらのPR によって導入され、v0.6.0 から上記の問題は発生しなくなりました。が、全角スペースが \u{3000} になったり、今回のバックスラッシュ2倍問題が発生したりと、数多のバグを発生させてしまいました。反省しています。
なぜバックスラッシュが2倍になるのか
今回の「バックスラッシュ2倍問題」がなぜ発生したのかを簡単に追ってみます。
まず、上で syn と proc_macro2 によって、スラッシュ3つのスタイルで書かれた doc comment は脱糖され、#[doc = "..."] の形に変換されると書きました。では、/// foo\bar と書かれた doc comment は、脱糖によってどういう形式になるのか気になります。Playground での実験の結果、以下のようになりました。
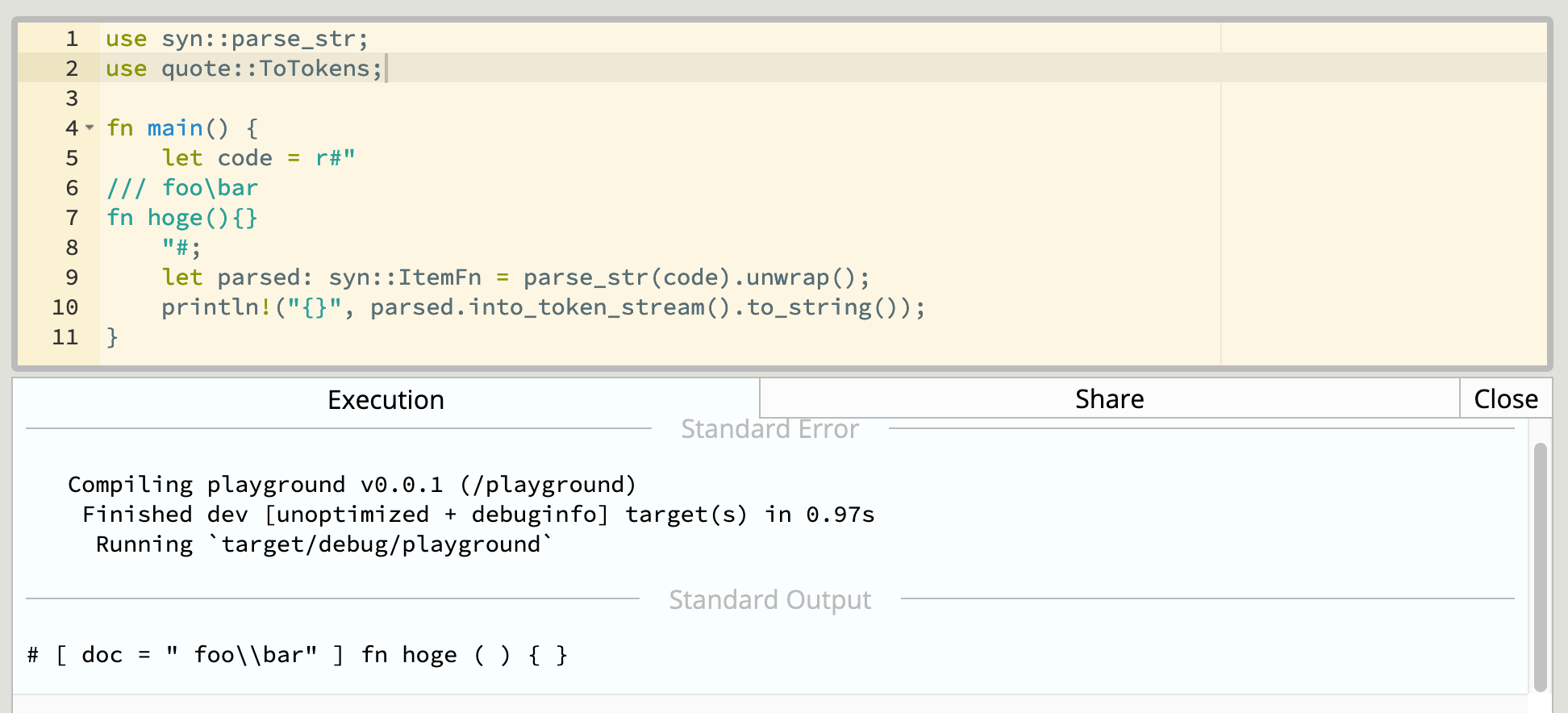
これを見て分かるのは、syn::parse_str をすることでバックスラッシュが2倍に増えている ということです。もともとは /// foo\bar だったものが、#[doc = "foo\\bar"] へと変換されています。
これはよく考えてみると当然で、変換前の /// foo\bar の段階ではバックスラッシュ1個でそのままバックスラッシュ1個を表現することができるのに対して、変換後の #[doc = "foo\\bar"] では、doc comment の中身がダブルクオートに囲まれていて、バックスラッシュ1個を表現するために、バックスラッシュをエスケープした \\ の形で書く必要があります。
このようにバックスラッシュの2倍化は本来は必要な処理なのですが、doc comment を再糖化してスラッシュ3つスタイルへと戻そうとしている我々にとっては、邪魔な存在です。#[doc = "..."] の ... 部分を使って /// ... というように変換する、という素直な処理をしてしまうと、バックスラッシュ2倍化状態を引き継いでしまうことになります。
これが、バックスラッシュ2倍化問題の原因です。
対処方法 バックスラッシュ半分化?
2倍化したバックスラッシュをそのまま引き継いでしまうのが問題なので、素直に考えれば バックスラッシュを半分化すればいい ということになります。実際、バックスラッシュに対してはこのアプローチは有効に働き、問題は解決します。
しかし伏兵がいました。上で syn::parse_str をすることでバックスラッシュが2倍に増えている と書きましたが、考慮すべきなのはバックスラッシュだけではなかったのです。例えばタブを考えてみます。Playground で /// foo\bar となっているところを /// foo\tbar としてみると、出力は以下のようになります。
# [ doc = " foo\\tbar" ] fn hoge ( ) { }
この結果も、文字列としての "\t" を表現するためにはバックスラッシュをエスケープする必要があるということを考えれば、納得できます。
では本物のタブを doc comment に含めるとどうなるかを試してみます。本物のタブというのは ASCII コードでいうところの9番のやつです。これを syn::parse_str にかけて文字列化したものを出力すると、以下のようになりました。
# [ doc = " foo\tbar" ] fn hoge ( ) { }
ダブルクオート内でタブを表現するには \t と書く、ということを考えれば、こちらも納得です。
では、 バックスラッシュ半分化 を、タブについて適用するとどうなるかを考えてみます。
#[doc = "foo\\tbar"] に対してバックスラッシュ半分化を適用して、再糖化すると /// foo\tbar になります。これはもともとのコードに書いていた doc comment そのものですので、正しい結果です。
一方、本物のタブ、#[doc = "foo\tbar"] について見てみると、こちらは半分化すべきバックスラッシュはないので、そのまま再糖化され、 /// foo\tbar になります。/// foo<本物のタブ>bar ではありません。元のコードには本物のタブを書いていたはずなのに、出力は見た目通りの \t になってしまいました。
これはどういうことかというと、syn::parse_str されると、もともと '\t' (本物のタブ)だったものが、 '\\' (バックスラッシュ単品) と 't' (単なるアルファベットの t ) に分解されてしまうということです。この挙動は、proc_macro2 内で、 doc comment に対して char::escape_debug - Rust が適用されていることによります。
したがって、再糖化するにあたって、'\\' と 't' が連続して出現しているから、これは元のコードだとタブだったはずなので、タブに変換します という処理も行わなければならないのです。
そんなこんなで、タブやエスケープされたダブルクオートにも対応した修正をしたものが以下のPRです。
出して30分で merge されました。爆速!hatooさんありがとうございます。
宣伝
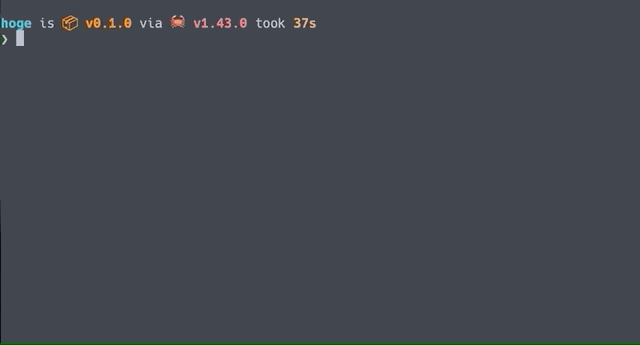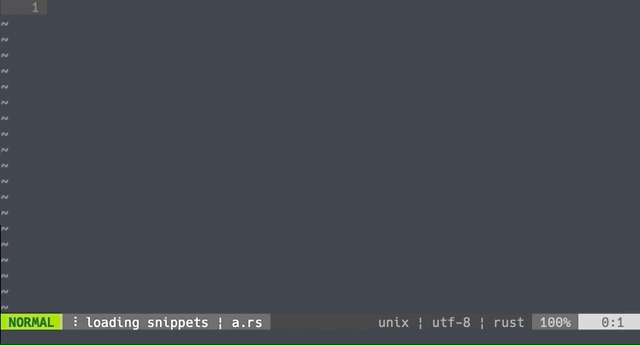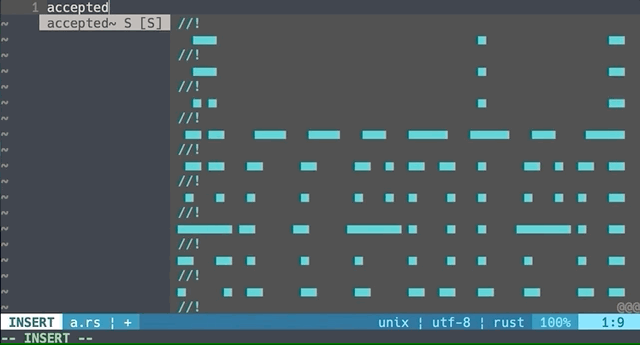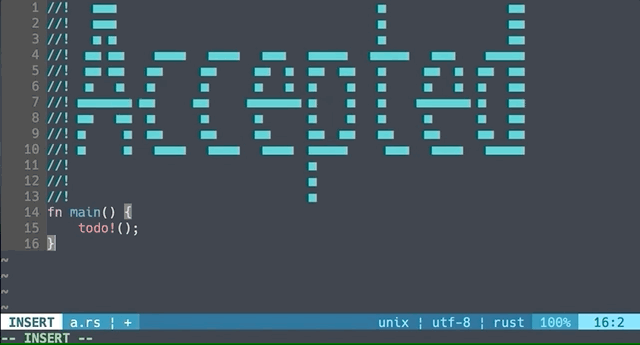
というわけで、素晴らしいスニペット管理ツール cargo-snippet で、スニペットにアスキーアートを書ける環境が整ってきています。
あなたも cargo-snippet を使ってスニペットにアスキーアートを載せて、自分の回答を見に来た人を驚かせてみませんか?(え?)
Accepted する自信に満ち溢れている人用のデモ